
NVIDIA時代のAIインターコネクト検証ホームラボ構成を考える
大規模言語モデル(LLM)の基盤構築において、ノード間インターコネクト(RDMAやRoCEv2)の性能がシステム全体を左右する時代になりました。Ultra Ethernet Consortium(UEC)による次世代規格の仕様策定も進んでおり、データセンターのネットワークアーキテクチャは大きな転換期を迎えています。
ネットワークインフラに携わるエンジニアとして、これらの通信プロトコルのパケットレベルの挙動(例えば、PFCによるポーズフレームの伝播や、ECNを活用した動的な輻輳制御の仕組み)を深く理解するためには、実際にパラメータを調整しながらパケットを観測できるマルチノードの検証環境が手元にあることが理想的です。
本記事では、AIインフラの標準であるNVIDIAの技術基盤を参考にしながら、「ネットワーク通信をパケットレベルで観察し、低レベルな制御を実現する」ためのホームラボ構成を検討します。
1. ターンキー構成の強みと、検証環境としての制約
卓上で小規模なAIクラスタ(2ノード構成など)を構築する場合、NVIDIA DGX SparkやASUS Ascent GX10といった、高速インターコネクトを内蔵したパーソナルAIノードを直結する構成が分かりやすい選択肢でしょう。
これらのシステムにはConnectX-7などの最新NICが標準搭載されており、RoCEv2やGPUDirect RDMAを手軽に検証できます。ベアメタルのLinux環境であるため、カーネルパラメータの調整や帯域制御など、OSレベルのチューニングも自由に行えるのが特徴です。AI開発に集中したいユーザーにとっては、電源を入れるだけで最高性能が得られる理想的な環境と言えます。
しかし、次世代ネットワークアーキテクチャをパケットレベルで理解し、低レイヤ制御を実践的に学びたい場合、この完成度の高さや専用設計が別の意味でハードルになり得ます。
- ハードウェアの柔軟性に欠ける
専用筐体のため、異なるNICへの差し替えが物理的に困難 - エコシステムの改変にリスクがある
ベンダー最適化された設定から意図的に変更すると、機器の性能を損なう可能性がある - 目的の不一致
ターンキーソリューションはAI開発向けの最適化が目的で、ネットワーク検証には不向き
ネットワーク技術の理解とスキル習得を目指すなら、コンポーネントを自由に入れ替えられる透過性の高いアーキテクチャを検討する価値があるでしょう。
2. 代替アーキテクチャ:透過性とプログラマビリティを優先する
ブラックボックス化を避け、データパスを完全に制御するためのコンポーネント選定を考えてみます。
2.1. GPUの選定:RDMAの前提と、ROCm系の選択肢
自作PCベースで安価にRDMAを検証する場合、最初に候補に挙がるのがGeForce RTXシリーズなどのコンシューマ向けGPUです。しかし、これらのGPUはNVIDIAのドライバレベルでGPUDirect RDMA(P2P DMA)が意図的に制限されているケースが多く見られます。
この制限がある場合、NICとGPU間の通信は必ずCPU経由のバウンスバッファを経由するため、RDMAの広帯域性能が活かせません。ワークステーション向けのRTX A6000などはGPUDirect RDMAをフルサポートしますが、コスト面でのハードルが上がります。
純粋なネットワーク検証が目的なら、ドライバレベルでの制限がないデータセンター向けGPUが適しています。NVIDIA以外ではAMD Instinctシリーズが現実的な選択肢でしょう。例えばInstinct MI100は、32GB HBM2メモリとPCIe 4.0 x16インターフェースを備えたデータセンター向けGPUとして提供されています。
ROCmは主としてオープンソースで構成されており(ドライバのAMDGPUからライブラリまで)、内部動作の追跡が比較的容易です。NVIDIAのNCCLと同様に、ROCmのcollective通信ライブラリであるRCCL1もオープンソースで公開されており、InfiniBand VerbsやTCP/IPソケット通信の最適化をコードレベルで確認できます。
ただし、ROCmはCUDAほど業界で普及していません。PyTorchなどの主要AI/MLフレームワークでの公式サポートやトラブルシューティング情報は限定的で、本格的なAIモデル開発や学習インフラとしての利用には課題が残ります。
一方、トラフィックジェネレータとしての活用や、低レイヤのネットワークプロトコル挙動の観測という本記事のスコープに絞れば、エコシステムの違いによるデメリットは許容範囲内と言えるでしょう。
2.2. NICの選定:UEC時代のデータプレーン
従来のRoCEv2環境では、固定機能ASICによる輻輳制御が主流でした。UECの登場により、アルゴリズムを動的に変更できるProgrammable Congestion Management(PCM)への移行が検討されています。この技術動向を踏まえた検証では、NICの選定基準にも新たな視点が求められます。
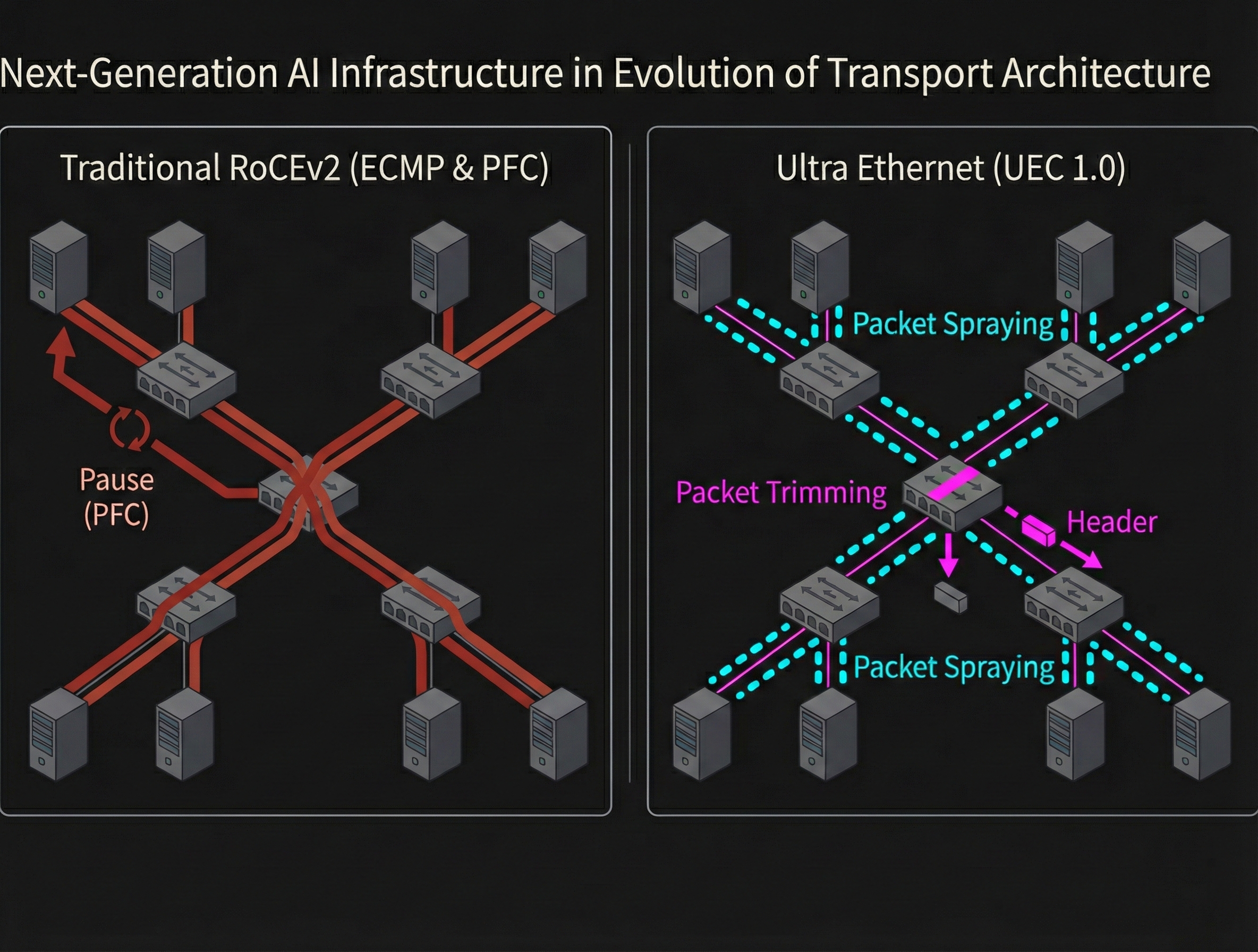
中古市場で比較的安価に入手できるConnectX-4/5/6といったASICベースのNICは、PFCやECNの標準的な挙動を検証するベースラインとして依然として重要です。枯れた技術であるこれらのNICは、安定したRoCEv2環境の構築に不可欠なコンポーネントと言えます。Mellanox以外にもIntel E810(irdmaドライバ)などRoCE/iWARP対応のNICは存在しますが、検証事例やツールの充実度ではConnectXシリーズが現時点で優勢です。
一方、UEC 1.0で提案されているマルチパス転送や次世代の輻輳制御ロジックを先取りして検証したい場合は、データプレーンの機能を後から更新できるDPU(Data Processing Unit)やSmartNICが有力な候補となります。例えばNVIDIA BlueFieldシリーズやP4言語対応のNICを使用すれば、以下のような検証が可能です:
- 新しい輻輳制御アルゴリズムのエミュレーション
- 高精度なインバンドテレメトリ(INT)によるキュー滞留状態の観測
ホームラボの構築では、段階的な展開が現実的でしょう:
- 初期段階ではConnectXシリーズなどの安価なNICでハードウェアオフロードの基本性能を測定する
- より高度な機能が必要になった段階で、DPU/SmartNICに移行してデータプレーンのプログラマビリティを活用する
このアプローチにより、予算制約を考慮しつつ技術進化に柔軟に対応できる実験環境を構築できます。
3. ホームラボを前提にしたスイッチ選定
家庭環境のホームラボでは、性能よりもまず電源容量・騒音・排熱の制約が現実的な課題となります。100G/400Gクラスのデータセンター向けスイッチは魅力的ですが、電力消費や騒音とのバランスが難しいのが現状です。UEC時代のネットワーク検証においては、搭載ASICの世代やパイプラインのプログラマビリティも重要な判断基準となります。
3.1. エンタープライズ向けスイッチの課題
中古市場ではMellanoxのSNシリーズやAristaなどのエンタープライズ向けスイッチが比較的安価に流通しています。しかし、これらの製品は消費電力が数百ワットに及び、騒音レベルもジェット機並みの80dBを超える場合があります。市販の静音ファンへの換装を試みるユーザーもいますが、100G以上のトランシーバは発熱が非常に大きいため、エアフローの低下は高価なASICチップの焼損につながりかねません。
3.2. キャンパス向けASICを流用する際の技術的限界
ホームラボ環境を構築する際、MikroTik CRS504のようなコスト効率の高い100Gスイッチは魅力的に映ります。しかし、RDMA/RoCEv2の100G検証環境として転用する場合、ASICアーキテクチャの根本的な制約が障害となります。
キャンパスネットワーク向けに設計されたチップは、データセンターやAIファブリックのような高負荷環境を想定していません。この設計思想の違いから、以下のような性能問題が発生しやすくなります:
- FECネゴシエーションの不安定性
- スイッチOSとデータセンター向けNICの組み合わせによっては、RS-FECの正常なネゴシエーションができず、100Gトランシーバを装着してもリンクが確立しない相性問題が頻発します
- バッファ容量の決定的な不足
- データセンターASICは大きな共有バッファ(例:Spectrum-2の42MBなど)を持つのに対し、キャンパス向け製品のバッファは限定的です。100Gbpsのバーストトラフィック発生時に即座にバッファが枯渇し、PFCの連続送信(PFCストーム)によって実効スループットが大幅に低下します
- CPU負荷の急激な上昇
- ハードウェアオフロード対象外のパケットが非力な管理用CPUに転送されると、ルーティング処理が追いつかずパフォーマンスが急激に劣化します
- 高度な輻輳制御・テレメトリの成熟度の限界
- 一部のキャンパス向けスイッチOSではPFC/ECN/WREDの基本的な設定が可能になり、RoCEv2向けの構成例が公式ドキュメントで提供されるケースも出てきました。しかし、高精度なハードウェアテレメトリ(INT/WJHなど)や、実験の再現性を担保する詳細な統計情報の取得機能は限定的です。パケットレベルの検証基盤としてはまだ課題が残ります
これらの安価なアグリゲーションスイッチは通常のL2/L3用途としては有用ですが、RDMA検証では機能不足が大きなボトルネックとなります。
3.3. UEC検証向けスイッチ選定 - 理想と現実のバランス
次世代のプロトコル処理を検証するプラットフォーム選定では、UECの全機能をネイティブサポートする最新機器と、個人が現実的に入手可能な機材の間に、価格と設備要件の面で克服困難な隔たりが存在します。
Packet TrimmingやAdaptive Routingをハードウェアで完全処理できる最新鋭機器(例:Broadcom Tomahawk 5搭載のFS N9600-64OD、NVIDIA Spectrum-4搭載のSN5600)は、1台あたり数万ドル以上のコストがかかります。消費電力も数千ワットに達するため、一般家庭の100V/15A電源環境では動作すらできません。
この現実を踏まえると、ホームラボでは「どの機能を必須とせず、どの部分まで検証可能か(サブセット検証)」の明確な定義が必要です。ここで重要な役割を果たすのが、ベンダー非依存のオープンネットワークOSであるSONiCです。SONiCは最新のネットワーク機能をテストする業界標準プラットフォームとして機能し、透過性向上・高度なテレメトリ取得・プログラマビリティの学習に柔軟な基盤を提供します。
これらの要件を満たす現実的な選択肢として、以下の条件に合うホワイトボックススイッチが候補となります。
- データセンター向けASIC世代(Trident 3以降 / Spectrum-2以降)であること
- プログラマブルなパイプラインと十分な共有バッファ(数十MB以上)を持つこと
- 中古市場で個人が調達可能な価格帯であること
- SONiCコミュニティビルドが安定動作すること
推奨機種比較
| モデル | ASIC | ポート構成 | 主な検証機能 | 中古価格(参考) |
|---|---|---|---|---|
| Edgecore AS7726-32X | Trident 3-X7 | 32×100G | IFA / DLB / 限定的プログラマブルパイプライン | ~$2,800 |
| Mellanox SN3700C | Spectrum-2 | 32×100G | WJH / 高度なRoCEv2バッファ管理(42MB) | ~$4,500 |
| Edgecore AS7326-56X | Trident 3 | 48×25G + 8×100G | INT / DLB / Leaf-Spine構成に最適 | ~$1,000–2,000 |
機種別の特徴
Edgecore AS7726-32X(Trident 3-X7) は、In-band Network Telemetry(INT)やダイナミックロードバランシング(DLB)をサポートするプログラマブルASICを搭載しています。UECのパケットトリミング機能こそ持ちませんが、パケットごとの遅延計測やバッファ占有率のテレメトリ取得が可能です。SONiCのコミュニティビルド(sonic-broadcom.bin)に公式対応しており、Intel Xeon D-1518搭載のコントロールプレーンも十分な処理能力を備えています。
Mellanox SN3700C(Spectrum-2) は、42MBの完全共有モノリシック・パケットバッファを備え、RoCEv2環境でのマイクロバーストを強力に吸収できます。最大の魅力はWJH(What Just Happened)機能で、パケットドロップの理由や輻輳の発生源をパケットレベルで正確に特定できるハードウェアテレメトリです。UECが目指す「エンドツーエンドの輻輳可視化」と同等の分析環境を構築するベースラインとして機能します。
Edgecore AS7326-56X(Trident 3) は、48ポートの25GbEダウンリンクと8ポートの100GbEアップリンクを備えています。データセンターで一般的なLeaf-Spineトポロジを安価に構築でき、25G SFP28ポートをネイティブに備えるため、ブレイクアウトケーブルによるFECの相性問題を回避できます。中古価格も$1,000〜$2,000と最もコストパフォーマンスに優れた選択肢です。
いずれの機種もデータセンター向けの高性能ファンを搭載しているため、家庭環境では防音ラックや別室への設置など、騒音対策が必須となります。
3.4. スイッチを使わない直結構成
ノードが2~3台程度であれば、スイッチを省略した構成も検討に値します。100G NIC同士をDAC(Direct Attach Cable)で直結すれば、騒音・発熱・電力消費の問題を完全に排除でき、NICレベルでのPFC動作を確実にテストできるでしょう。
ただし、ECNの検証にはトラフィックジェネレータでCEビットを人為的に付与する必要があり、スイッチ起因の輻輳は再現できません。3台以上の構成ではルーティング設定が複雑化し、ネットワーク検証以外の運用コストが増える可能性もあります。
ホームラボの構築においては、性能追求だけでなく、搭載ASICの世代とパイプラインの能力、実際の運用環境の制約を十分に考慮した機器選定が重要です。目的に応じて適切な構成を選択すれば、限られたリソースでもUEC時代のネットワーク検証に向けた有意義な学習環境を構築できます。
4. パケットの可観測性に関する考察
4.1. ソフトウェア実装RDMAの活用シーン
Soft-RoCE(RXE / rdma_rxe)は、RoCEv2のプロトコル処理をNICではなくCPUでエミュレートする技術です。IBのBTHをUDPパケットにカプセル化するため、ハードウェアオフロードを使わない環境ではtcpdumpやWiresharkでRoCEv2相当のパケットを観測できます。ヘッダ形式やECNビットの変化を確認する学習用途に適した手段でしょう。
一方、Soft-RoCEは主要ディストリビューションで “Technology Preview” あるいは “deprecated” とされる例があります。RHELでは不安定性を理由に非推奨とされ、将来リリースでの削除予定2が明記されています。このため、初期の学習や最小構成での動作確認に用途を限定するのが現実的です。
4.2. ハードウェアオフロード時に観測が難しくなる理由
RoCEv2とRDMA NICの組み合わせでハードウェアオフロードを活用する場合、ホスト上の通常のパケットキャプチャでは観測できる情報が限られます。以下のような複合的なアプローチが有効です:
- スイッチのミラーポート(SPAN/ERSPAN)の活用
- RDMAがCPUをバイパスしても、パケット自体はネットワーク上を流れるため、物理層でのパケット取得は有効な手段です
- NICの輻輳関連カウンタの監視
- rdmaコマンドによる統計情報の取得
- iproute2の
rdmaサブコマンドはstatisticやmonitorオプションを備えており、RDMA関連の統計情報を詳細に取得できます
- iproute2の
4.3. eBPFを用いた高度な観測
ハードウェアオフロードされたRoCEv2では、データパケットがカーネルのネットワークスタックを完全にバイパスします。そのため、XDPやTCなどの通常のeBPFフックではペイロードを捕捉できません。ただし、以下の観測は可能です:
- コントロールプレーンの追跡
- RDMA接続確立時のCM(Connection Manager)状態遷移を、カーネル内のフックで捕捉する
- ドライバレベルの監視
- RDMAドライバ(
ib_core等)の統計情報や状態変化を、低オーバーヘッドで記録する
- RDMAドライバ(
- BCCツールの活用
- Red Hatのドキュメント5でも紹介されているように、BCC(eBPFベースのトレーシングツール群)でネットワーク関連のイベントを効率的に観測できる
これらの手法を組み合わせれば、ハードウェアオフロード環境でもネットワーク挙動の詳細な可視化が可能になります。
5. おわりに
ラボ環境の構築において、目的によって選択すべきアーキテクチャは大きく異なります。AIモデルの開発や学習をできるだけ早く始めたい場合は、NVIDIA DGXなどのターンキーソリューションが最適でしょう。
一方、ネットワークエンジニアとしてプロトコルの詳細な検証やデータプレーンの挙動解析を行いたい場合には、最適化されたエコシステムからあえて離れ、コンポーネント単位で自由に構成を組むアプローチが有効です。制約の多いホームラボ環境でも、ROCm環境の構築やSONiCとホワイトボックススイッチの組み合わせにより、パケットレベルでのネットワーク可視化やプログラマブルなデータプレーン操作を体験できます。
PFCやECNのパラメータ調整、パケットレベルでの挙動観察は、UECをはじめとする次世代インターコネクト技術を理解する上で貴重な一次情報となります。本記事が、ネットワークの透過性とプログラマビリティを追求するエンジニアの皆様にとって、ラボ環境構築のヒントになれば幸いです。
🤖 本記事はLLMで情報収集を行い、PLaMoの支援を受けて文章を推敲しました。事実確認を含む最終的な内容は、筆者が責任を持って作成しています。
Footnotes
-
https://github.com/ROCm/rocm-systems/tree/develop/projects/rccl ↩
-
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/9/html/configuring_infiniband_and_rdma_networks/configuring-roce_configuring-infiniband-and-rdma-networks ↩
-
https://blogs.oracle.com/linux/rocev2-congestion-counters-explained ↩
-
https://www.arista.com/assets/data/pdf/Broadcom-RoCE-Deployment-Guide.pdf ↩
-
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/8/html/configuring_and_managing_networking/network-tracing-using-the-bpf-compiler-collection_configuring-and-managing-networking ↩