
Designing a Homelab for AI Interconnect Verification in the NVIDIA Era
Interconnect performance between nodes — RDMA and RoCEv2 in particular — now determines overall system performance in large language model (LLM) infrastructure. With the Ultra Ethernet Consortium (UEC) actively developing next-generation specifications, data center network architecture is at a major turning point.
As a network infrastructure engineer, the ideal way to deeply understand the packet-level behavior of these protocols — how PFC pause frames propagate, how ECN-based dynamic congestion control works — is to have a multi-node test environment where you can tune parameters and observe packets firsthand.
In this post, I explore how to build a homelab environment focused on observing network traffic at the packet level and achieving low-level control, drawing on the NVIDIA technology stack that has become the standard for AI infrastructure.
1. Turnkey Systems: Strengths and Limitations as a Test Environment
When building a small AI cluster on a desk (say, a two-node setup), the most straightforward approach is to directly connect personal AI nodes like the NVIDIA DGX Spark or the ASUS Ascent GX10, which have high-speed interconnects built in.
These systems ship with state-of-the-art NICs such as the ConnectX-7, making it easy to test advanced features like RoCEv2 and GPUDirect RDMA. Since they run bare-metal Linux, you can freely adjust kernel parameters and configure bandwidth controls — OS-level tuning is wide open. For users who want to focus on AI development, these are ideal: just power on and get peak performance.
However, if your goal is to deeply understand next-generation network architectures at the packet level and practice low-layer control, this very completeness and purpose-built design can become a barrier.
- Limited hardware flexibility The dedicated chassis makes it physically difficult to swap in different NICs.
- Risk of modifying the ecosystem Intentionally changing vendor-optimized configurations may degrade system performance.
- Mismatch in purpose Turnkey solutions are optimized for AI development, not for network verification.
If your aim is to understand networking technology and build practical skills, it is worth considering a transparent architecture where you can freely swap components.
2. An Alternative Architecture: Prioritizing Transparency and Programmability
Let’s look at component selection that avoids black-box designs and gives you full control over the data path.
2.1. GPU Selection: The RDMA Prerequisite and ROCm as an Option
When trying to verify RDMA inexpensively on a custom-built PC, consumer GPUs like the GeForce RTX series are the first candidates that come to mind. However, NVIDIA’s drivers often intentionally restrict GPUDirect RDMA (P2P DMA) on these GPUs. In that case, communication between the NIC and GPU must go through a CPU bounce buffer, which negates the high-bandwidth advantage of RDMA and creates a bottleneck. (Workstation-class GPUs like the RTX A6000 do fully support GPUDirect RDMA, but they are significantly more expensive.)
For pure network verification, data center GPUs with no driver-level restrictions are the better fit. Outside the NVIDIA ecosystem, the AMD Instinct series is a realistic option. The Instinct MI100, for example, is a data center GPU with 32 GB of HBM2 memory and a PCIe 4.0 x16 interface. ROCm is primarily open source — from the AMDGPU driver to the libraries — which makes it relatively easy to trace internal behavior. Like NVIDIA’s NCCL, ROCm’s collective communication library RCCL1 is also open source, allowing you to inspect InfiniBand Verbs and TCP/IP socket optimizations at the code level.
That said, ROCm is not as widely adopted as CUDA. Official support and troubleshooting resources for major AI/ML frameworks like PyTorch are limited. This makes ROCm less suitable for full-scale AI model development and training infrastructure. However, if you limit the scope to using it as a traffic generator or observing low-level network protocol behavior — the focus of this article — the downsides of the ecosystem difference are acceptable.
2.2. NIC Selection: The Data Plane in the UEC Era
With the arrival of UEC, there is a shift from the fixed-function ASIC congestion control that dominated traditional RoCEv2 environments toward Programmable Congestion Management (PCM), which allows dynamic algorithm changes. When testing with this technology trend in mind, NIC selection criteria differ from the conventional approach.
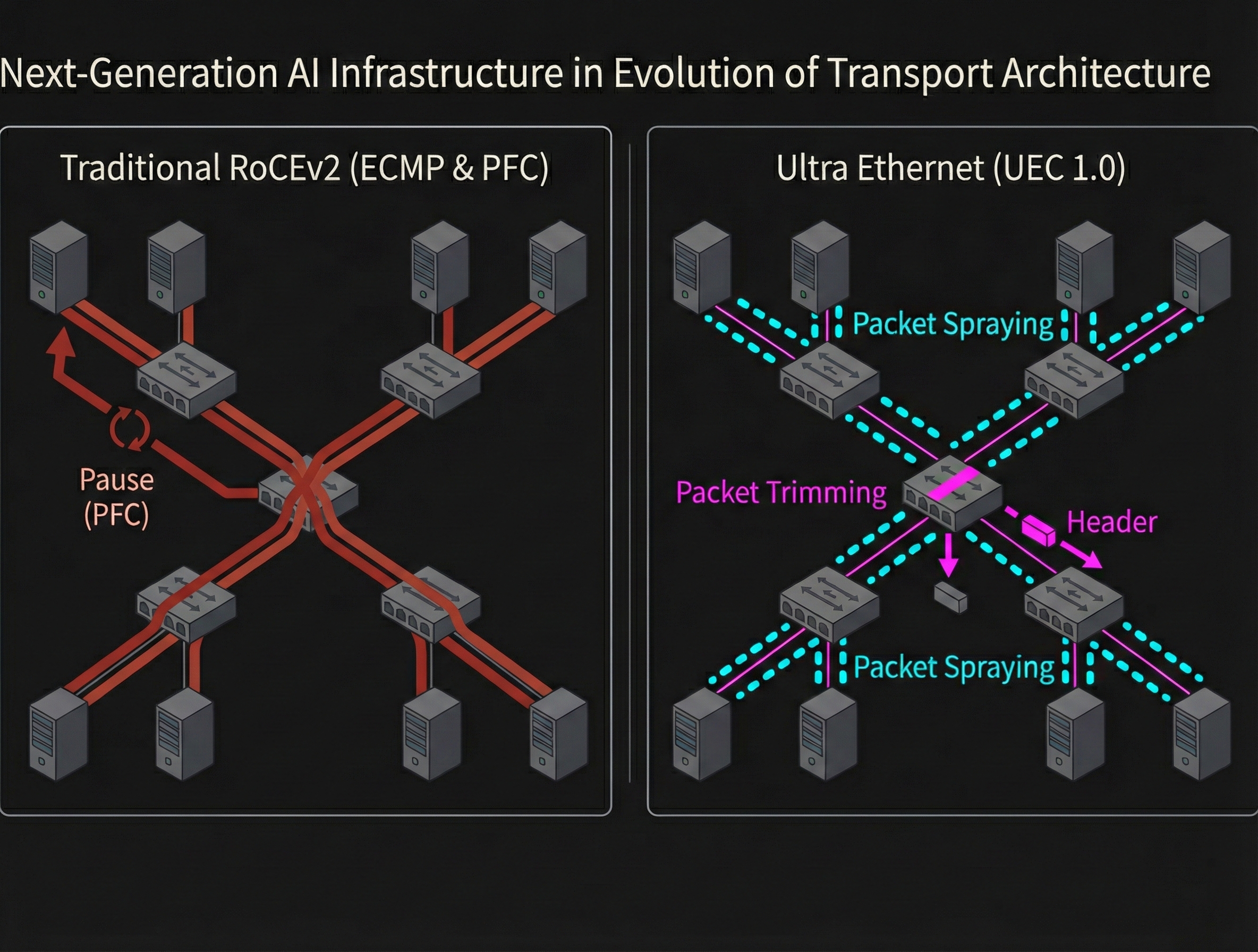
Standard ASIC-based NICs like the ConnectX-4/5/6, which are relatively affordable on the used market, still play an important role as baselines for verifying standard PFC and ECN behavior. These well-established NICs are essential components for building a stable RoCEv2 environment. Besides Mellanox, other RoCE/iWARP-capable NICs like the Intel E810 (irdma driver) exist, but the ConnectX series currently has the edge in verification examples and tooling.
On the other hand, if you want to get ahead and test multipath forwarding and next-generation congestion control logic proposed in UEC 1.0, DPUs (Data Processing Units) and SmartNICs — whose data plane functions can be updated after deployment — are strong candidates for prototyping new algorithms. With NVIDIA BlueField series devices or NICs that support the P4 language, you can:
- Emulate new congestion control algorithms
- Observe detailed queue occupancy states using high-precision In-band Network Telemetry (INT)
A realistic approach for building a homelab is a phased rollout:
- Start with affordable NICs like the ConnectX series to measure baseline hardware offload performance.
- Migrate to DPUs/SmartNICs when more advanced network features are needed, leveraging data plane programmability.
This approach lets you build a test environment that adapts to technological evolution while staying within budget.
3. Switch Selection for a Homelab
In a homelab at home, practical constraints — power capacity, noise, and heat dissipation — matter more than raw performance. Data center switches in the 100G/400G class offer impressive throughput, but balancing their power consumption and noise against a residential environment is challenging. For UEC-era network verification, the generation and pipeline programmability of the switch ASIC also become critical selection criteria.
3.1. The Challenge of Enterprise Switches
Enterprise switches like the Mellanox SN series and Arista products are available at relatively low prices on the used market. However, they can consume several hundred watts of power and produce noise levels exceeding 80 dB — comparable to a jet engine. Some users attempt to replace the fans with quieter aftermarket models, but 100G+ transceivers generate significant heat. Reduced airflow risks burning out expensive ASIC chips.
3.2. Technical Limitations of Repurposing Campus-Grade ASICs
When building a homelab, cost-effective 100G switches like the MikroTik CRS504 look appealing. However, repurposing them for RDMA/RoCEv2 100G verification runs into fundamental ASIC architecture limitations.
Chips designed for campus networks were not intended for the high-load conditions of data center or AI fabrics. This design philosophy mismatch leads to several serious performance issues:
- FEC negotiation instability
- Certain combinations of the switch OS and data center NICs fail to negotiate RS-FEC properly. Even with 100G transceivers installed, the link may not come up due to compatibility issues.
- Critically insufficient buffer capacity
- Data center ASICs designed for RDMA often have large shared buffers (e.g., 42 MB on Spectrum-2), while campus-grade products have much smaller buffers. When 100 Gbps burst traffic hits, buffers are exhausted immediately, and continuous PFC transmission (PFC storms) drastically reduces effective throughput.
- Sudden CPU load spikes
- Packets that cannot be hardware-offloaded are forwarded to the underpowered management CPU. Routing processing falls behind, causing rapid performance degradation.
- Limited maturity of advanced congestion control and telemetry
- Recent versions of some campus switch operating systems do support basic PFC/ECN/WRED configuration, and official documentation now includes RoCEv2 configuration examples. However, the high-precision hardware telemetry (INT, WJH, etc.) and detailed statistics collection found in data center ASICs remain limited. As a detailed packet-level verification platform, these switches still have gaps.
These affordable aggregation switches are perfectly useful for standard L2/L3 networking, but their feature gaps become a major bottleneck for RDMA verification.
3.3. Switch Selection for UEC Verification: Balancing the Ideal and Reality
When selecting a platform for next-generation protocol verification, there is a formidable gap in price and facility requirements between the ideal cutting-edge gear that natively supports all UEC features and equipment that an individual can realistically obtain.
State-of-the-art switches capable of handling Packet Trimming and Adaptive Routing entirely in hardware — such as the FS N9600-64OD (Broadcom Tomahawk 5) or the NVIDIA SN5600 (Spectrum-4) — cost tens of thousands of dollars each and draw several thousand watts. They simply cannot run on a typical household 100 V / 15 A outlet.
Given this reality, a homelab must clearly define which features can be omitted and what subset of verification is feasible, then select equipment accordingly. This is where SONiC — a vendor-neutral, open network OS — plays a key role. SONiC serves as an industry-standard platform for testing the latest network features, providing a flexible foundation for improving network transparency, collecting advanced telemetry, and learning programmability.
White-box switches that meet the following criteria are the realistic choice:
- Data center ASIC generation (Trident 3 or later / Spectrum-2 or later)
- Programmable pipeline with sufficient shared buffer (tens of MB or more)
- Priced within individual reach on the used market
- Stable operation with SONiC community builds
Recommended Models
| Model | ASIC | Port Configuration | Key Verification Features | Used Price (approx.) |
|---|---|---|---|---|
| Edgecore AS7726-32X | Trident 3-X7 | 32×100G | IFA / DLB / limited programmable pipeline | ~$2,800 |
| Mellanox SN3700C | Spectrum-2 | 32×100G | WJH / advanced RoCEv2 buffer management (42 MB) | ~$4,500 |
| Edgecore AS7326-56X | Trident 3 | 48×25G + 8×100G | INT / DLB / ideal for leaf-spine topologies | ~$1,000–2,000 |
Model Highlights
Edgecore AS7726-32X (Trident 3-X7) features a programmable ASIC that supports In-band Network Telemetry (INT) and Dynamic Load Balancing (DLB). While it lacks UEC’s packet trimming, it can measure per-packet latency and collect buffer occupancy telemetry. It is officially supported by the SONiC community build (sonic-broadcom.bin) and has a capable Intel Xeon D-1518 control plane.
Mellanox SN3700C (Spectrum-2) has a 42 MB fully shared monolithic packet buffer that absorbs microbursts effectively in RoCEv2 environments. Its standout feature is WJH (What Just Happened), a hardware telemetry function that pinpoints the exact reason for packet drops and the source of congestion at the packet level. It serves as a baseline for building an analysis environment equivalent to the end-to-end congestion visibility that UEC aims to achieve.
Edgecore AS7326-56X (Trident 3) provides 48 × 25 GbE downlink ports and 8 × 100 GbE uplink ports, enabling you to build the leaf-spine topology most common in data centers at a low cost. Because it has native 25G SFP28 ports, you avoid the FEC compatibility issues caused by breakout cables that occur with MikroTik devices. Its used price of $1,000–$2,000 also makes it the most cost-effective option.
All of these models have high-performance data center fans. Running them at home requires noise mitigation such as a soundproof rack or placing them in a separate room.
3.4. Direct-Connect Without a Switch
In some cases, eliminating the switch entirely is worth considering. With two or three nodes, you can connect 100G NICs directly using a DAC (Direct Attach Cable). This completely eliminates noise, heat, and power consumption issues, and lets you reliably test PFC behavior at the NIC level. However, to verify ECN you would need a traffic generator to artificially set the CE bit, and you cannot reproduce switch-induced congestion. With three or more nodes, routing configuration becomes complex, and operational overhead outside of network verification may increase.
When building a homelab, it is important to consider not only raw performance but also the ASIC generation, pipeline capabilities, and the practical constraints of your operating environment. By choosing an appropriate configuration for your goals, you can build a meaningful learning environment for UEC-era network verification even with limited resources.
4. Thoughts on Packet Observability
4.1. When to Use Software-Implemented RDMA
Soft-RoCE (RXE / rdma_rxe) emulates RoCEv2 protocol processing in software on the CPU rather than in NIC hardware. Because it encapsulates IB BTH into UDP packets, you can observe RoCEv2-equivalent packets with tcpdump or Wireshark in environments that do not use hardware offload. It is particularly useful for learning about header formats and ECN bit changes.
However, Soft-RoCE is marked as a “Technology Preview” or “deprecated” in major distributions. For example, RHEL explicitly states that it is not recommended due to instability and is scheduled for removal in a future release2. In practice, Soft-RoCE should be limited to early learning and minimal-configuration smoke testing.
4.2. Why Observation Gets Harder with Hardware Offload
When using hardware offload with RoCEv2 and an RDMA NIC, standard packet capture on the host provides limited visibility. A multi-layered approach is more effective:
- Switch mirror ports (SPAN/ERSPAN)
- Even when RDMA bypasses the CPU, packets still travel over the network. Capturing them at the physical layer is a viable approach.
- NIC congestion-related counters
- The
rdmacommand for statistics- The
rdmasubcommand in iproute2 providesstatisticandmonitoroptions for collecting detailed RDMA statistics.
- The
4.3. Advanced Observation with eBPF
In hardware-offloaded RoCEv2, data packets completely bypass the kernel network stack. Standard eBPF hooks like XDP and TC cannot capture the payload. However, the following observations are possible:
- Control plane tracing
- Capture CM (Connection Manager) state transitions during RDMA connection establishment using in-kernel hooks.
- Driver-level monitoring
- Record statistics and state changes from RDMA drivers (
ib_core, etc.) with low overhead.
- Record statistics and state changes from RDMA drivers (
- BCC tools
- As documented by Red Hat5, BCC (a set of eBPF-based tracing tools) can efficiently observe network-related events.
Combining these techniques appropriately makes detailed network behavior visualization possible even in hardware-offloaded environments.
5. Conclusion
The right architecture for a lab environment depends heavily on your goals. If you want to start developing and training AI models as quickly as possible, a polished turnkey solution like the NVIDIA DGX series is the best choice.
On the other hand, if you are a network engineer looking to verify protocol details and analyze data plane behavior, it is more effective to step away from optimized ecosystems and build your configuration from individual components. Even in a resource-constrained homelab, combining a ROCm environment with SONiC and white-box switches lets you experience packet-level network visualization and programmable data plane operations firsthand.
Hands-on work — tuning PFC and ECN parameters, observing packet-level behavior — yields valuable first-party insights for understanding next-generation interconnect technologies like UEC. I hope this article serves as a useful starting point for engineers pursuing network transparency and programmability in their lab environments.
🤖 This article was researched and drafted with LLM assistance, including PLaMo for prose refinement. All facts and final content are the author’s responsibility. The English version was translated from the Japanese original by Claude Opus 4.6.
Footnotes
-
https://github.com/ROCm/rocm-systems/tree/develop/projects/rccl ↩
-
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/9/html/configuring_infiniband_and_rdma_networks/configuring-roce_configuring-infiniband-and-rdma-networks ↩
-
https://blogs.oracle.com/linux/rocev2-congestion-counters-explained ↩
-
https://www.arista.com/assets/data/pdf/Broadcom-RoCE-Deployment-Guide.pdf ↩
-
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/8/html/configuring_and_managing_networking/network-tracing-using-the-bpf-compiler-collection_configuring-and-managing-networking ↩